Hadoop Ecosystem

Welcome to my world of Internet of Things and Cloud Computing. I received my bachelor's degree in the discipline of Internet of Things. I also write technical articles. I am now pursuing a Masters degree in Cloud Computing. I am an Amazon Web Services Certified Cloud Practitioner.
In this article, I will cover following topics -
1. Introduction
2. What does Hadoop Ecosystem means?
3. Components of Hadoop Ecosystem
~ HDFS
~ HBase
~ Yarn
~ Sqoop
~ Apache Spark
~ Apache Flume
~ MapReduce
~ Apache Pig
~ Hive
~ Zookeeper
~ Storm
~ Oozie
4. Conclusion
Introduction
The Internet, as we all know, has transformed the electronic sector, and the quantity of data created by nodes is huge, leading in a data revolution. Because data is so large, it necessitates the usage of a platform to handle it. Hadoop Architecture helps to schedule jobs and minimizes the number of people on the task.
What does Hadoop Ecosystem mean?
Hadoop Ecosystem is a platform or framework that handles big data challenges. Consider it a suite that contains a number of services (ingesting, storing, analyzing, and maintaining).
Components of Hadoop Ecosystem
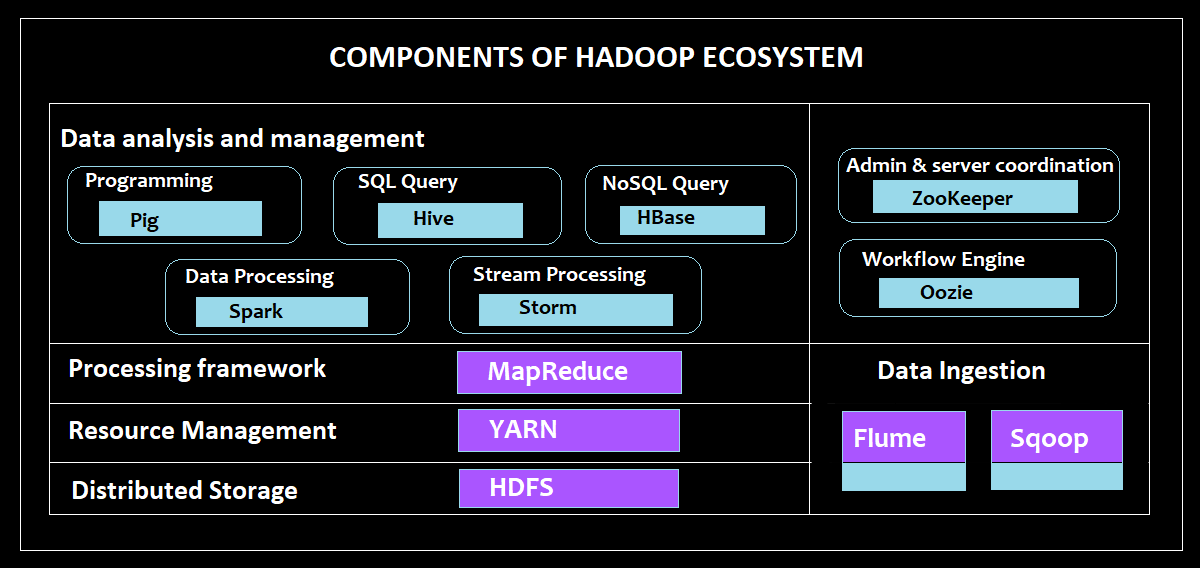
1~ Hadoop Distributed File System
 Hadoop's backbone is the Hadoop Distributed File System, which operates on the Java programming language and stores data in Hadoop applications.
HDFS consists of two parts:
Hadoop's backbone is the Hadoop Distributed File System, which operates on the Java programming language and stores data in Hadoop applications.
HDFS consists of two parts:
- data node
- name node.
The name node is in charge of managing file systems, operating all data nodes, and keeping track of metadata updates. When data is deleted, it is automatically recorded in the Edit Log. Because of the reading and writing activities, the Data Node (Slave Node) requires a lot of storage capacity. They function in accordance with the Name Node's instructions.
2~ HBASE
It is an open-source framework that can store any form of data but does not support SQL databases. They are developed in Java and run on top of HDFS. Most businesses utilize them because of their characteristics like as support for all sorts of data, strong security, and HBase tables. They are critical in the analysis process. HBase's two main components are-
- HBase master
- Regional Server
The HBase master is in charge of load balancing and failover in a Hadoop cluster. They are in charge of completing administrative duties. The regional server would act as a worker node, reading and publishing data in the cache.
3~ YARN
 It is a key component of the Hadoop ecosystem and is known as an operating system in Hadoop, which offers resource management and task scheduling. The components include a resource and node manager, an application manager, and a container. They also serve as protectors for Hadoop clusters. They aid in the dynamic allocation of cluster resources, speed up data center processes, and enable various access engines.
It is a key component of the Hadoop ecosystem and is known as an operating system in Hadoop, which offers resource management and task scheduling. The components include a resource and node manager, an application manager, and a container. They also serve as protectors for Hadoop clusters. They aid in the dynamic allocation of cluster resources, speed up data center processes, and enable various access engines.
4~ Sqoop
It's a tool that helps you move data between HDFS and MySQL and gives you instructions on how to import and export data. They also provide a connector for gathering and connecting data.
5~ Apache Spark
It's a key data processing engine and an open-source data analytics cluster computing architecture. It's written in Scala and comes with a set of standard libraries. Because of their high processing speed and stream processing, many industries rely on them.
6~ Apache Flume
It's a distributed service that gathers massive quantities of data from a source (webserver), sends it back to the source, and then stores it in HDFS. The three components are the source, sink, and channel.
7~ Map Reduce
 It is in charge of data processing and is a key component of Hadoop. Map Reduce is a parallel processing engine that runs across several computers within the same cluster. This approach is developed in Java and is based on the divide and conquer strategy. Parallel processing aids in the quick process of avoiding traffic congestion and efficiently improving data processing.
It is in charge of data processing and is a key component of Hadoop. Map Reduce is a parallel processing engine that runs across several computers within the same cluster. This approach is developed in Java and is based on the divide and conquer strategy. Parallel processing aids in the quick process of avoiding traffic congestion and efficiently improving data processing.
- The map function takes a collection of data and turns it into another set of data, with individual items split down into tuples (key/value pairs).
- The Reduce function takes the Map output as an input, combines those data tuples depending on the key, and adjusts the value of the key appropriately.
8~ Apache Pig
Data from Apache Pig Hadoop manipulation is handled by Apache Pig, which employs the Pig Latin Language. It promotes code reuse and makes code easier to understand and develop.
9~ Hive
It is an open-source platform for implementing data warehousing concepts; it is capable of querying large data sets stored in HDFS. It is based on the Hadoop Ecosystem. Hive Query language is the language used by Hive. The user provides hive queries with metadata, which transforms SQL into Map-reduce jobs and sends them to the Hadoop cluster, which is made up of one master and many slaves.
10~ Apache Zookeeper
It is an API that aids in the coordination of distributed systems. An application in the Hadoop cluster creates a node named Znode in this case. They provide services such as synchronization and configuration. It solves the time-consuming coordination problem in the Hadoop Ecosystem.
11~ Storm
Storm is a computing framework for distributed stream processing developed mostly in the Clojure programming language. After being bought by Twitter, the software was open sourced by Nathan Marz and his colleagues at BackType.
12~ Oozie
Oozie is a java web application that manages a large number of workflows in a Hadoop cluster. Controlling a task from anywhere is made possible by using Web service APIs. It is well-known for its ability to handle several tasks efficiently.
Conclusion
This ends a quick overview of the Hadoop Ecosystem. Apache Hadoop has grown in popularity owing to capabilities such as data stack analysis, parallel processing, and fault tolerance. Ecosystems' key components are Hadoop Common, HDFS, Map-reduce, and Yarn. To create a viable solution, it is important to understand a collection of Components; each component performs a certain function as part of the Hadoop Functionality.




